Fix crawled not currently indexed content in GSC

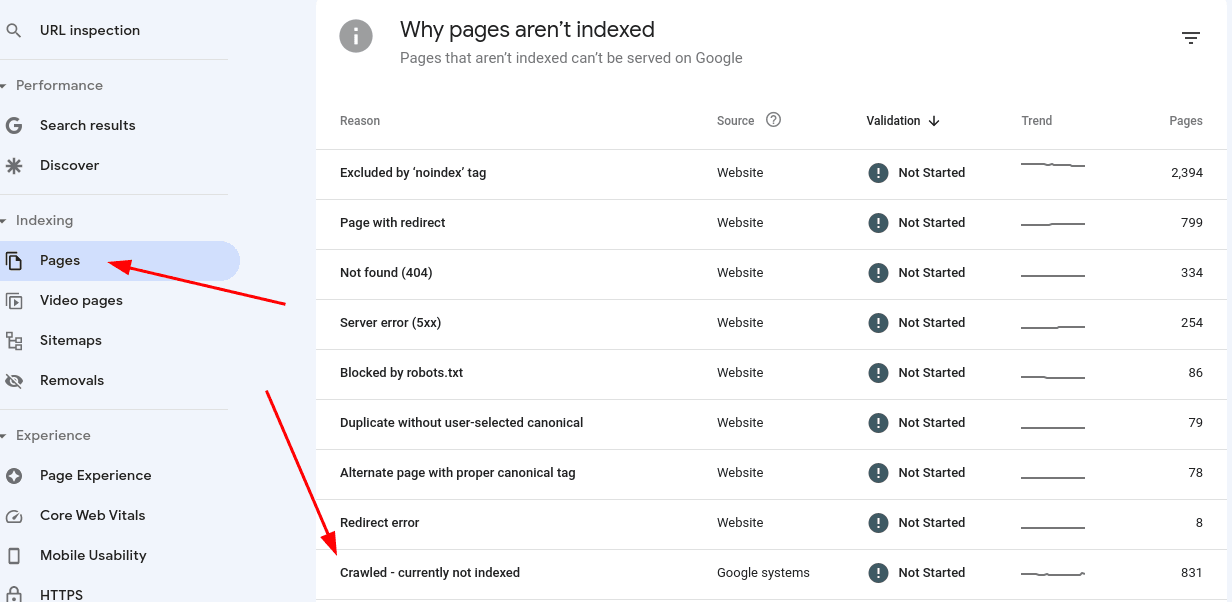
Fix crawled not currently indexed content in GSC
Crawled Currently Not Indexed Content
How to fix website content that is Crawled - currently not indexed in Google
Google Search Console provides a listing of all URLs that are crawled but not currently indexed. This is some of the most interesting and telling data about how Google grades individual pages on your website. Let’s explore the different types of crawled but not indexed content and how to get the URL indexed and appearing in Google search results for your target keywords.
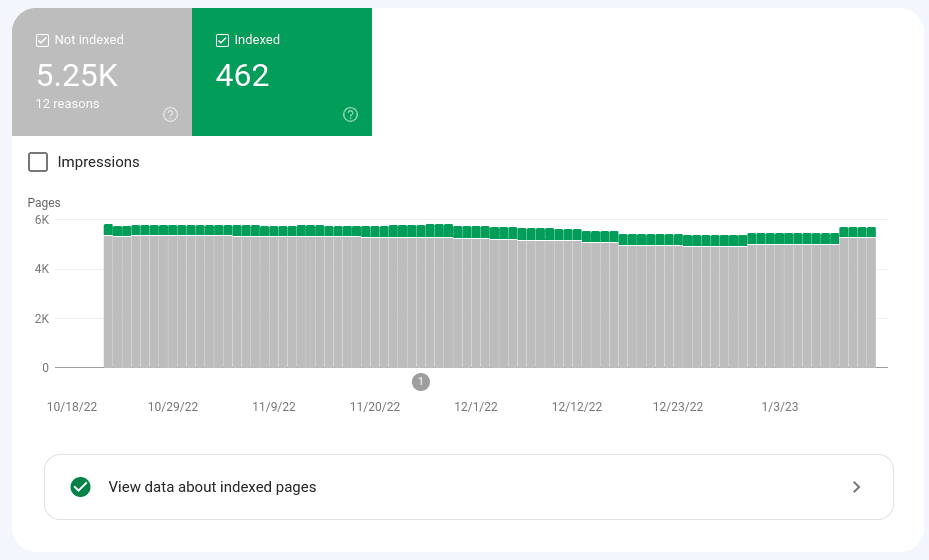
The difference between being crawled and being indexed
A URL, or an entire site, is crawled when a Google bot visits the page or site. Google tells you the last crawled date within Search Console. You can also look for Googlebot visits in your server logs. Just make sure they match known googlebot IP addresses because fake googlebots are common. To see known Googlebot IP addresses go here https://developers.google.com/static/search/apis/ipranges/googlebot.json and here’s how you verify that it is actually a google-bot: https://developers.google.com/search/docs/crawling-indexing/verifying-googlebot A URL or an entire website is indexed when the page or all pages of the site appear in Google search results for specific terms. Indexed is synonymous with being included in search results. If the URL is included in search results it would not be appearing in the list that we are discussing in Google Search Console. The goal of every content creator is getting every URL into search results for the right keyword phrases.

When to worry about your no index ratio
A soft rule is when you have more than 15% of your pages crawled and not indexed there’s probably a technical issue. Those technical SEO issues could include wrong canonicals, duplicate content, thin content, mismatched headers, and worse of all a noindex being set.
Discovered Currently Not Indexed Caused by Large Number of URLs
Discovered not indexed is an interesting categorization by Google systems. Typically, these are caused by a large number of URLs, either old or new, that are found by Google, or known by Google, but not fully crawled yet because they do not want to overload your server. What is interesting about this list, is we often see subdomains included that are on many different servers. It’s a tell that Google is focused on the domain more than the server.
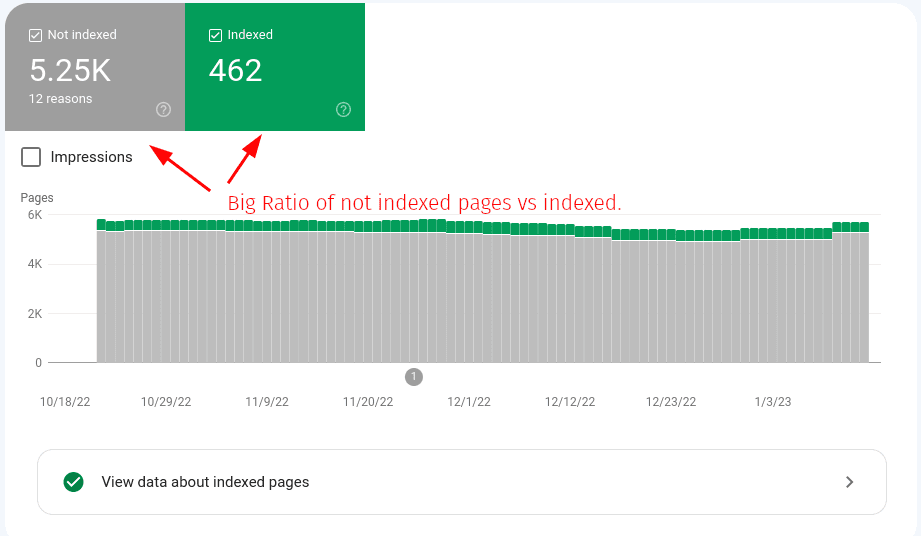
By spot checking many of these URLs you often see the “discovered currently not indexed” list is behind the rest of your Search Console report. If you are checking and you see many of the URLs in this list are actually indexed then try to run the validation and come back to recheck in 36 hours.
Pages that are crawled but not indexed
This is where it gets interesting. To analyze pages that are indexed but not showing in results we’re going to go to our handy flow chart. The general questions you ask include: Is the page new? If yes, when was it published? How much traffic does your site get? Do you get more than 10k unique visits per day? If yes, does your site appear in news results? If yes, then the url should appear in the Google index very quickly after publication (minutes). When you start hitting no answers you have to decide if you want to keep, kill, or combine the content with other content on your site.
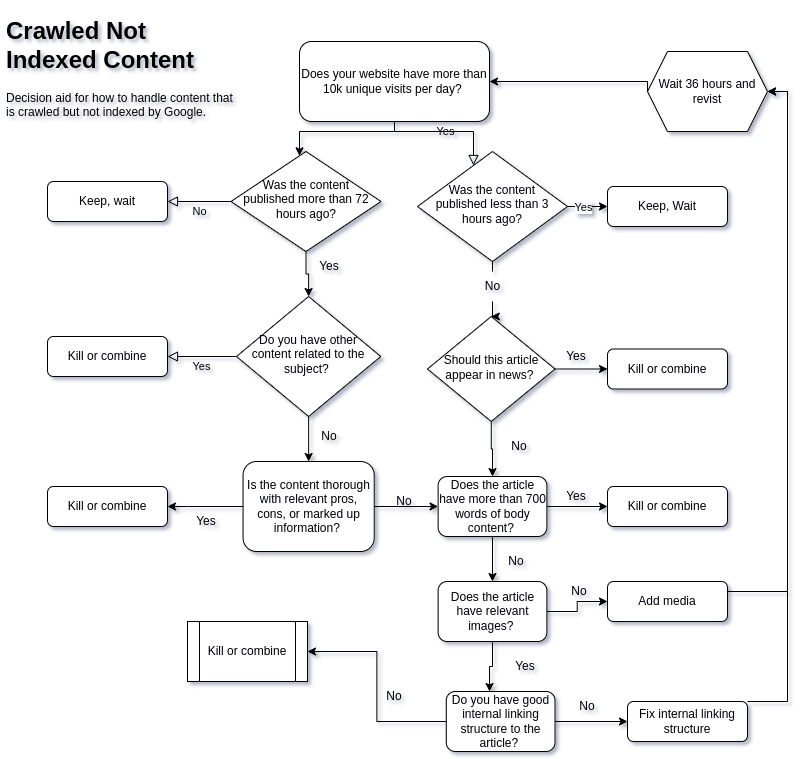
You can copy the flowchart and use it for your own use here: https://github.com/fruition/crawled-not-indexed
How to Fix Crawled not Indexed
We’re going to assume the basic technical SEO items are taken care of. This includes ensuring there is not a noindex tag, that you have a title tag, and meta description that is related to the content. Next we have to assume your content has good structure to it including H1, H2, H3 elements, that your images have alt tags and the content isn’t AI generated fluff. If all of those are taken care of then we have to get into the meat of the content.
The number 1 most often reason for content being crawled and not indexed is that it isn’t unique enough from other content on your site that covers the same subject. If you’re trying to get multiple articles or pages ranked for the same subject you may run into this often.
As we focus on the informative nature of your content, if it isn’t adding more to your story, or your answer, then it won’t rank. To sort through these related pages of content that aren’t ranking we’ll go through a Keep, Kill or Combine exercise. A Keep, Kill or Combine exercise is easy if you only have a handful of pages with overlapping content. It gets complicated when you have thousands of pages of content, tens of thousands of images, and hundreds of keyword targets.
How long does it take for crawled not index website urls to get indexed
For high traffic websites with more than 10k unique visitors per day new crawls happen within a few minutes. For lower traffic websites it can also happen fast but typically once per day. For the typical B2B website it may take a few days to a few weeks depending upon how often your content changes and how time sensitive the content is.
How to Monitor Results of Getting URLs Crawled
Seeing page views with source organic is the best way to see the results of your efforts. It’s also the most foolproof way to know that you are getting organic traffic from a previously crawled but not indexed site. If you would like assistance with this Google indexing issue we offer content specific services to get your site performing at a high level. Reference page for this is Google’s official documentation posted here: https://support.google.com/webmasters/answer/7440203#discovered__unclear_status
Noindex Checker
If you’re worried about a bigger noindex tag problem. Check out our noindex checker.
Lets Chat Indexing Problems
We’re hear to discuss your indexing problems!



